
So what if I didn’t need to write Terraform code?
In the beginning…
So this whole story starts with me looking to manage my DNS records better.
I wrote a whole blog post about it if you’re interested: Moving my DNS records to Route 53 with Terraform
I was modifying them by hand in our domain registrar’s own DNS settings page… and it was kinda a pain.
At work we use AWS Route 53 for some DNS records, so I was familiar with how that worked, and it seemed like a good idea to move to that too. Not because managing DNS records in Route 53 by hand is much easier, but it opened up the possibility for automating it.
Terraform!
Which is where Terraform comes in!
Before we can create some DNS records, we need a hosted zone
It’s prety simple to create one. Just needs a name:
resource "aws_route53_zone" "lmhd-me" {
name = "lmhd.me"
}
I will want to delegate the test subdomain to a different zone too:
resource "aws_route53_record" "lmhd-me_NS_test-lmhd-me" {
zone_id = aws_route53_zone.lmhd-me.zone_id
name = "test.lmhd.me"
type = "NS"
ttl = "300"
records = aws_route53_zone.test-lmhd-me.name_servers
}
I don’t need to do that, but I like that separation, and it gives me the flexibilty to move that to an entirely different AWS account (or somewhere else) in future.
The first problem I encounted almost immediately was that you can’t do CNAMEs on apex domains, and I wanted to do something for lmhd.me.
Route 53 doesn’t have a concept of an “ANAME”. So I would have to roll my own.
Thankfully, Terraform has a DNS Provider so I could query for the IP Address of my Netlify site, and then use that when defining my A Record for lmhd.me:
# Lookup CNAME for Netlify.
data "dns_cname_record_set" "lmhd-dot-me-netlify-com" {
host = "lmhd-dot-me.netlify.com"
}
# Get IPs for that CNAME
data "dns_a_record_set" "netlify-com" {
host = data.dns_cname_record_set.lmhd-dot-me-netlify-com.cname
}
# Set up the A record for lmhd.me
resource "aws_route53_record" "lmhd-me-A-record" {
zone_id = aws_route53_zone.lmhd-me.zone_id
name = "lmhd.me"
type = "A"
ttl = "300"
records = ["${data.dns_a_record_set.netlify-com.addrs}"]
}
The rest of the records are fairly simple. Most are just CNAMEs, and have similar format to the above.
I set this up to run in Terraform Cloud, and away I went, adding new DNS records as and when I needed them. For example:
resource "aws_route53_record" "widgets-lmhd-me-CNAME-record" {
zone_id = aws_route53_zone.lmhd-me.zone_id
name = "widgets.lmhd.me"
type = "CNAME"
ttl = "300"
records = ["lmhd-widgets.netlify.app"]
}
Okay, this is getting tedious
I’m lazy efficient, so I don’t want to have to write out all of that every time I want to add something.
Can we make it easier on ourselves?
What if we make TF Variables out of this?
Took a bit of fiddling to get something which works, but here’s what I came up with as my initial version:
#
# DNS Records
#
variable "lmhd_records" {
type = map(object({
type = string
ttl = string
records = list(string)
}))
default = {
"widgets.lmhd.me" = {
type = "CNAME"
ttl = "300"
records = ["lmhd-widgets.netlify.app"]
}
}
}
#
# DNS Records
#
resource "aws_route53_record" "lmhd_record" {
for_each = var.lmhd_records
zone_id = aws_route53_zone.lmhd-me.zone_id
name = each.key
type = each.value.type
ttl = each.value.ttl
records = each.value.records
}
This makes use of Terraform’s for_each Meta-Argument, so rather than defining a Terraform resource for every DNS record, I define a single resource and update the variable instead.
And our plan looks like this:
# aws_route53_record.lmhd_record["widgets.lmhd.me"] will be created
+ resource "aws_route53_record" "lmhd_record" {
+ allow_overwrite = (known after apply)
+ fqdn = (known after apply)
+ id = (known after apply)
+ name = "widgets.lmhd.me"
+ records = [
+ "lmhd-widgets.netlify.app",
]
+ ttl = 300
+ type = "CNAME"
+ zone_id = "REDACTED"
}
That’s… okay. Maybe slightly less typing… but now it’s messy. Why would I want to do this?
And if I stopped there, I would agree, it’s not really worth it.
But it is a stepping stone in the right direction: getting automatically generated TF code!
Auto-generated TF code
Can I use external files to auto-generate my Terraform code?
And… yes. Terraform has a bunch of functions, including fileset which lets me query the content of a directory.
First we need to pull in some files…
locals {
lmhd_records_files = fileset(path.module, "lmhd.me/*.json")
}
output "lmhd_records" {
value = local.lmhd_records_files
}
This gives us a list of all JSON files in the lmhd.me/ directory:
Changes to Outputs:
+ lmhd_records = [
+ "lmhd.me/widgets.lmhd.me.json",
]
So that’s a start.
That one JSON file of mine looks like this:
{
"type": "CNAME",
"ttl": "300",
"records": [
"lmhd-widgets.netlify.app"
]
}
And we can pull that in with Terraform making use of a few other functions:
resource "aws_route53_record" "lmhd_record" {
for_each = local.lmhd_records_files
zone_id = aws_route53_zone.lmhd-me.zone_id
# Use the filename as the name of the DNS record
# e.g. lmhd.me/widgets.lmhd.me.json --> widgets.lmhd.me
name = trimsuffix(basename(each.key), ".json")
# Get the rest of the values from keys in the JSON file
type = jsondecode(file(each.key))["type"]
ttl = jsondecode(file(each.key))["ttl"]
records = jsondecode(file(each.key))["records"]
}
Our plan looks like this:
# aws_route53_record.lmhd_record["lmhd.me/widgets.lmhd.me.json"] will be created
+ resource "aws_route53_record" "lmhd_record" {
+ allow_overwrite = (known after apply)
+ fqdn = (known after apply)
+ id = (known after apply)
+ name = "widgets.lmhd.me"
+ records = [
+ "lmhd-widgets.netlify.app",
]
+ ttl = 300
+ type = "CNAME"
+ zone_id = "REDACTED"
}
Looking good 🙂
But… I like YAML… 👉👈
Okay, fine…
Our widgets.lmhd.me.yaml file:
type: CNAME
ttl: 300
records:
- lmhd-widgets.netlify.app
locals {
lmhd_records_files = fileset(path.module, "lmhd.me/*.yaml")
}
resource "aws_route53_record" "lmhd_record" {
for_each = local.lmhd_records_files
zone_id = aws_route53_zone.lmhd-me.zone_id
# Use the filename as the name of the DNS record
# e.g. lmhd.me/widgets.lmhd.me.json --> widgets.lmhd.me
name = trimsuffix(basename(each.key), ".yaml")
# Get the rest of the values from keys in the YAML file
type = yamldecode(file(each.key))["type"]
ttl = yamldecode(file(each.key))["ttl"]
records = yamldecode(file(each.key))["records"]
}
Happy?
Some validation
That works fine as an initial Proof of Concept… but what if I’ve not specified some of those keys in my file?
In my case, most of these values are going to be the same.
I’m primarily defining CNAMEs, and I rarely change the TTL.
So I kinda don’t really want to have to specify them in my files every time.
Can we do something about that?
And… yes we can.
Let’s have a YAML file like this:
records:
- lmhd-widgets.netlify.app
And some Terraform code like this:
variable "default_ttl" {
type = string
default = "300"
}
resource "aws_route53_record" "lmhd_record" {
for_each = local.lmhd_records_files
zone_id = aws_route53_zone.lmhd-me.zone_id
# Use the "name" key if specified
# otherwise fallback to filename, minus .yaml
name = lookup(
yamldecode(file(each.key)),
"name",
trimsuffix(basename(each.key), ".yaml")
)
# Default to CNAME type unless told otherwise
type = lookup(
yamldecode(file(each.key)),
"type",
"CNAME"
)
# Use Default TTL unless told otherwise
ttl = lookup(
yamldecode(file(each.key)),
"ttl",
var.default_ttl
)
# We must have some records, otherwise this will fail
records = yamldecode(file(each.key))["records"]
}
Now, if I do not specify some of those values, it will use the defaults.
I can also override the name of the DNS record if I so chose.
That last bit, if we do not specify any records in our YAML file, Terraform spits out the following error message:
╷
│ Error: Invalid index
│
│ on lmhd.me.tf line 348, in resource "aws_route53_record" "lmhd_record":
│ 348: records = yamldecode(file(each.key))["records"]
│ ├────────────────
│ │ each.key is "lmhd.me/widgets.lmhd.me.yaml"
│
│ The given key does not identify an element in this collection value.
Which is okay. You can figure out what’s gone wrong there.
We can’t add custom error messages, because we can’t use validation blocks, as those don’t exist for resources, only variables.
Great! But… Why?
I mean, why go through all this effort, when you could just write the Terraform code?
What’s wrong with this?
resource "aws_route53_record" "widgets-lmhd-me-CNAME-record" {
zone_id = aws_route53_zone.lmhd-me.zone_id
name = "widgets.lmhd.me"
type = "CNAME"
ttl = "300"
records = ["lmhd-widgets.netlify.app."]
}
And besides the obvious answer of “I’m doing this because it’s fun…
It actually does have some valid use-cases.
A couple years ago I did a talk at HashiConf about how we generate Terraform code for our Vault configuration.
You can watch it here later:
The short version though… our pipeline generates Terraform code. So for example, if a user wants to add a new policy, they don’t worry about writing the Terraform code for that, they just raise a Pull Request which contains the policy itself, and our pipeline figures out the rest.
That was originally done with some bash scripts… which it turns out, once we had several hundred, was pretty slow.
So we rewrote it in Go and now it’s faster.
But what if we didn’t need any external tools in the first place?
What if we could just have Terraform do all the hard work?
That’s how I’ve been approaching Terraforming my own personal Vault.
So let’s see if I can improve that with some sort of dynamic Terraform like we’ve seen above.
Vault Terraform 2.0
Let’s start with policies, as those are the easiest to conceptualise.
It’s just one file, and you want the content of each of those files to become policies in Vault.
#
# Dynamic Policies from Files
#
locals {
policy_files = fileset(path.module, "policies/*.hcl")
}
resource "vault_policy" "policies" {
for_each = local.policy_files
# Use the name of the policy file as the name of the policy
name = trimsuffix(basename(each.key), ".hcl")
# And use the content of the file as the policy itself
policy = file(each.key)
}
So for an example policy…
# vault_policy.policies["policies/test.hcl"] will be created
+ resource "vault_policy" "policies" {
+ id = (known after apply)
+ name = "test"
+ policy = <<-EOT
# Test policy
# Just comments
# doesn't actually do anything
EOT
}
Hey! That looks pretty good 😀
One thing to note though is I’ve had to manually remove the existing policies from Terraform State, so that Terraform doesn’t delete anything. e.g.
$ terraform state rm vault_policy.vault_terraform
Acquiring state lock. This may take a few moments...
Removed vault_policy.vault_terraform
Successfully removed 1 resource instance(s).
$ terraform state rm vault_policy.default
Acquiring state lock. This may take a few moments...
Removed vault_policy.default
Successfully removed 1 resource instance(s).
I could re-import those policies into the Terraform state if I wanted to, so the resulting Terraform plan is a no-op… but as writing Vault policies is idempotent, I’m not really bothered for the moment.
Something I would definitely want to do in a Production environment though.
Let’s load test this for funsies!
As we’ve added more things to our Vault Terraform pipeline at work, the amount of time it takes for the pipeline to run end-to-end is… well, it’s longer than I’d like.
So what if we had like… 10k policies?
How would Terraform Cloud handle that?
Let’s generate a bunch of test policies:
$ for i in $(seq 1 10000); do echo "# test policy ${i}" > test_policy_${i}.hcl; done
Yeah, let’s just casually add about 5MiB to this git repo. No big deal. 😎
Writing objects: 100% (10003/10003), 528.05 KiB | 5.33 MiB/s, done.
Unsurprisingly, simply cloning this chonky boi took Terraform Cloud quite a while.
It wasn’t until about 4 minutes in that it actually started planning anything.
So… maybe I should at least give it a chance with a smaller set first, and go from there.
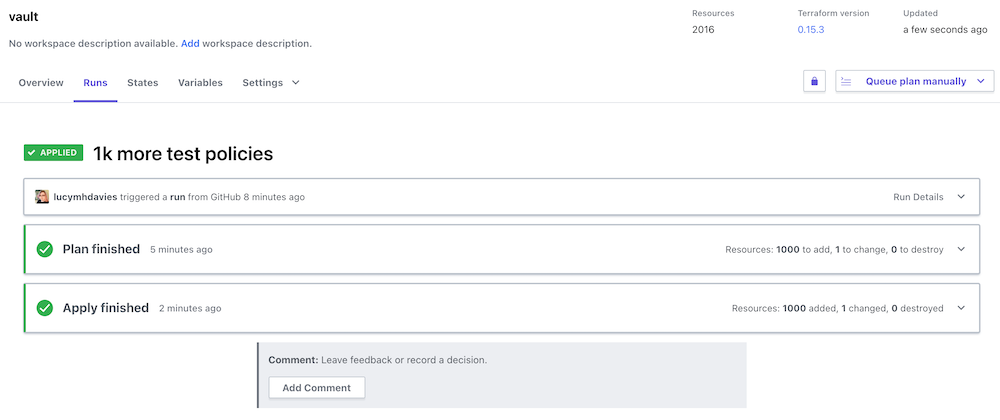
With a mere 1000 test policies, it took under a minue to Plan, and a similar amount of time to Apply.
Nice.
And adding another 1000?
3 minute plan, 3 minute apply. So 6 minutes end-to-end, with over 2000 resources configured through Terraform.
Pretty good.
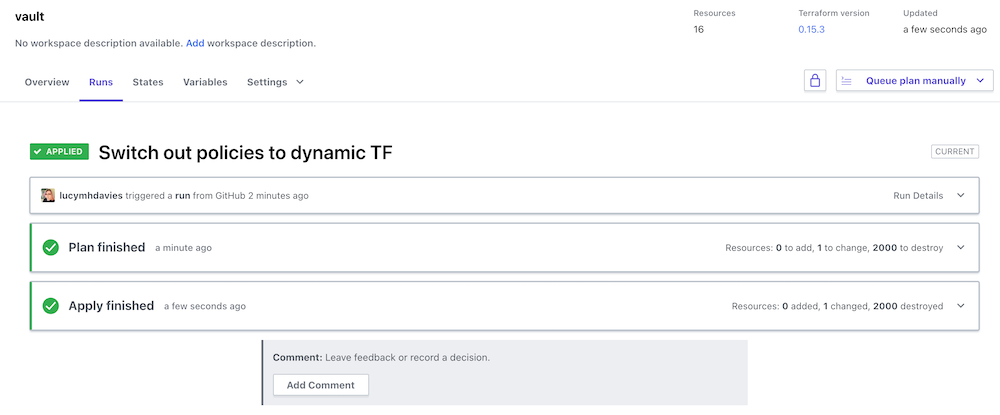
And to delete them all once I’m done?
About a minute and a half, end-to-end.
Dang that’s great!
What next?
For me, the next thing I’m going to work on is AppRoles and PKI roles, and then see where we go from there. But that’s a job for another day.
If I were setting up a Vault Terraform pipeline in a new company for the first time, this is definitely the approach I’d want to take.
As much off-the-shelf as possible, and and minimal external dependencies.